- Published on
Decomposing the Red Hat AI Platform Dashboard
- Authors

- Name
- Eder Ignatowicz
- @ederign
This is a post about UI architecture, specifically how we decomposed the Red Hat AI platform dashboard from a monolith into a modular architecture.
AI platforms are not just another SaaS surface. They sit between exploratory computing, infrastructure APIs, and rapidly evolving model ecosystems. That combination creates architectural pressures that do not appear in traditional product UIs.
The Red Hat AI Dashboard faced three compounding pressures:
- Kubernetes API coupling. Direct Kubernetes API access is how most K8s dashboards start. It becomes a structural problem when AI services multiply and each UI action fans out across multiple CRDs and service endpoints.
- Team scaling. Rapid team scaling driven by the AI exponential growth turns a monolithic codebase into an organizational bottleneck.
- Upstream-first contribution. Code must flow across upstream (Kubeflow), midstream (Open Data Hub), and enterprise (Red Hat AI) layers. A monolith cannot cleanly separate what belongs where.
Each pressure alone has simpler solutions. Together, they demand a coordinated response: micro-frontends via Module Federation, a Backend for Frontend with OpenAPI contracts that enable parallel UI development from day one, and deliberate organizational design following Team Topologies. Not one of these. All three, simultaneously.
The pace of AI innovation compounds all three: new capabilities emerge faster than backend services can stabilize, and UI teams are blocked waiting for APIs that are still being defined.
So the question becomes:
How do you ship an AI platform UI when the backend is a moving target, the team is scaling faster than the codebase can absorb, and your code must serve both open-source communities and enterprise products?
Hi, I'm Eder, the architect behind the UI transformation of the Red Hat AI dashboard. Over the past eighteen months, I identified the structural problems in a monolithic frontend that could not scale, designed the modular architecture to replace it, and shaped the team topology to execute it. Together with Red Hat leadership and my Staff Engineers and leads, I led its adoption across the organization. The results:
- 4 modules in production (Model Registry, Model Catalog, GenAI Studio, Model Serving) and 6+ in progress, including Notebooks, Pipelines, EvalHub, AutoRAG, and others
- 8+ teams shipping independently, developing and validating on their own cadence
- UI development decoupled from backend. Teams start building before AI service APIs are ready, via OpenAPI contracts and BFF mocks
- Red Hat: #1 contributor to Kubeflow. UI engineers now contribute upstream alongside backend teams, enabled by the modular architecture
- Codebase that AI tools can reason about. Self-contained modules with OpenAPI contracts and typed extensions give AI coding assistants bounded context, the same architectural boundaries that help human engineers also help AI tools
The summary above covers the what and the results. The rest of this post covers the why: the pressures we faced, the decomposition we chose, and why each piece was necessary.
What This Post Covers
- Three Compounding Pressures. Kubernetes API coupling, team scaling, and upstream-first contribution: the forces that outgrew our monolithic frontend.
- Why the Naive Approach Fails. Micro-frontends solve team velocity but leave the structural problems untouched.
- The Boundary That Actually Matters. Three simultaneous decompositions: organizational design via Team Topologies, runtime composition via Module Federation, and a Backend for Frontend that separates infrastructure concerns from UI development.
- Module and Open Source Extension Mechanism. How extension points enable upstream-downstream coexistence without forking, the piece most micro-frontend articles miss.
- Operational Consequences. Clusterless development, team velocity, and upstream impact: what changes when the architecture is in place.
- Context Boundaries and AI Tooling. Why the same context shrinking that helps human engineers also makes the codebase something AI coding assistants can reason about effectively.
This work is the result of multiple months of effort across the entire Red Hat AI Core Dashboard organization. I want to highlight Jen, Catherine, Dana, and Sherard for their leadership, sponsorship and support, my former manager Gabe, my ❤️ Staff Engineers Andy, Andrew, Anthony, and Christian for driving the technical excellence, and Lucas and Jenny from the Monarch team, key contributors who have been instrumental in bringing this vision to life.
Three Compounding Pressures
Three forces converged in the Red Hat AI platform dashboard as it grew from a single-team project into a multi-team enterprise product. Each alone has simpler solutions. Together, they demanded a coordinated architectural response.
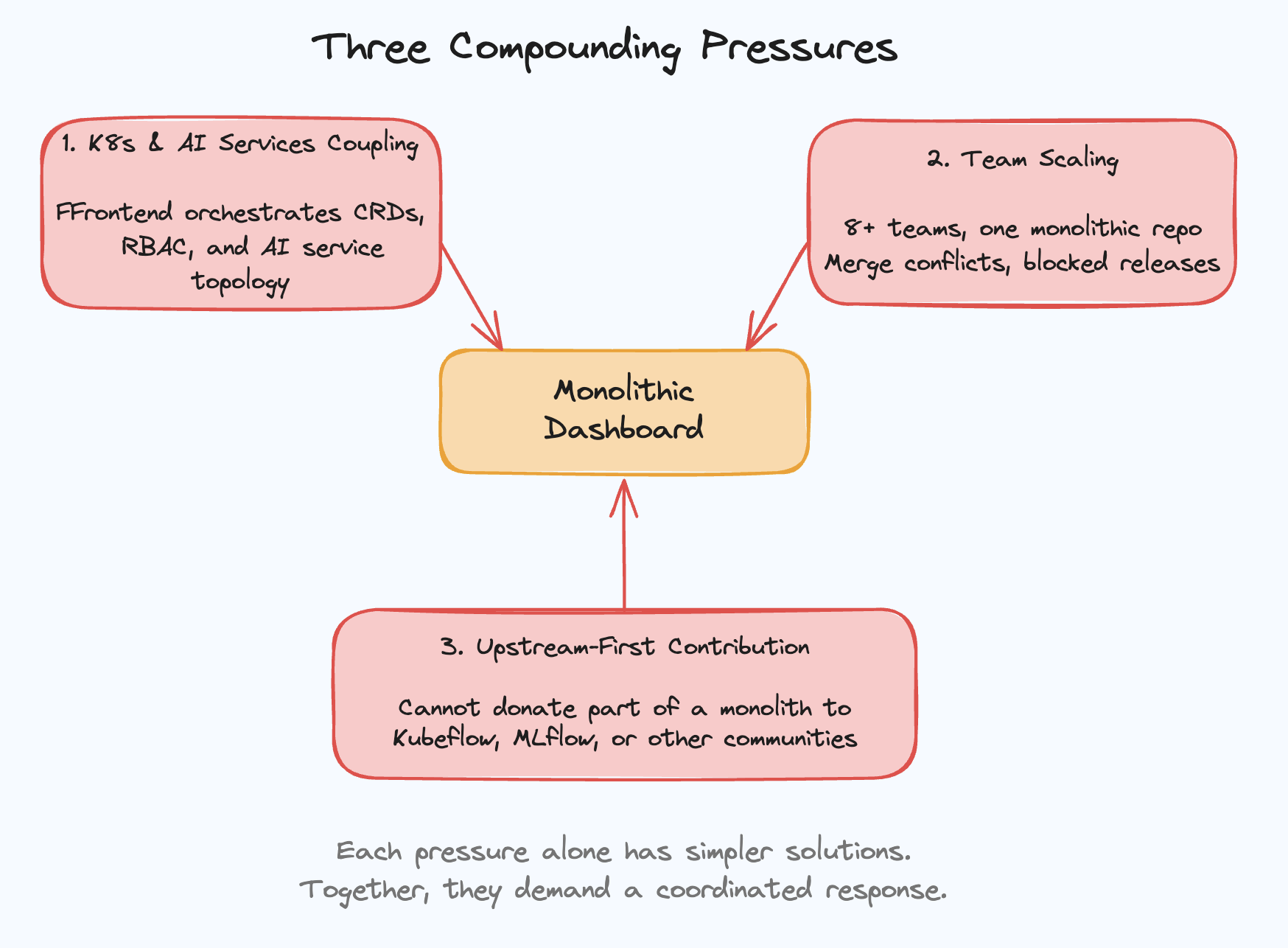
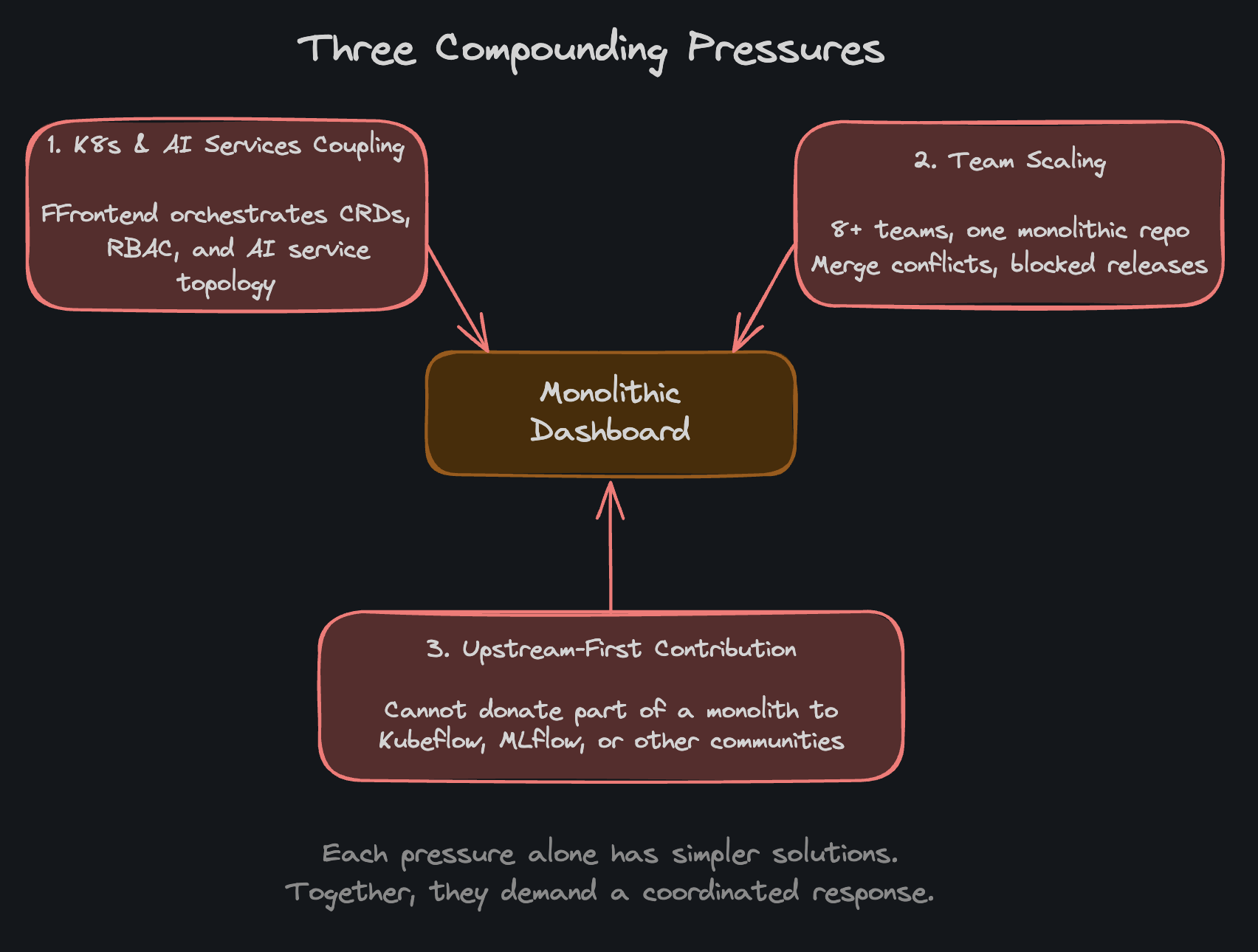
1. Kubernetes and AI Services API Coupling
Most Kubernetes dashboards start with the frontend calling Kubernetes APIs, whether directly or through a passthrough proxy. For a small team with a contained scope, this is the right approach: it is the fastest path to a working UI. But as the platform grows, as AI services multiply, and as each user action fans out across more CRDs and service endpoints, the coupling becomes a structural problem. The frontend code still owns the Kubernetes resource knowledge, the orchestration logic, and the error handling for every API call. These are not frontend concerns, but without a domain-specific API layer, they accumulate in the UI code.
Consider what happens when a user creates a notebook server. The UI must:
- Create a PersistentVolumeClaim for workspace storage
- Create ConfigMaps for environment variables
- Create Secrets for registry credentials and tokens
- Create the Notebook Custom Resource that references all of the above
- Watch the Notebook status for readiness, surfacing errors from pod scheduling, image pulling, and resource quota violations
Each of these operations requires knowledge of Kubernetes API conventions: resource versioning, label selectors, owner references, finalizers. A frontend developer fixing a form validation bug must navigate RBAC policies and Custom Resource Definition schemas to understand the data flow.
GenAI features compound this further. A chat interface (from the user's perspective, a single text input and a response stream) requires the frontend to reach across an entire service topology:
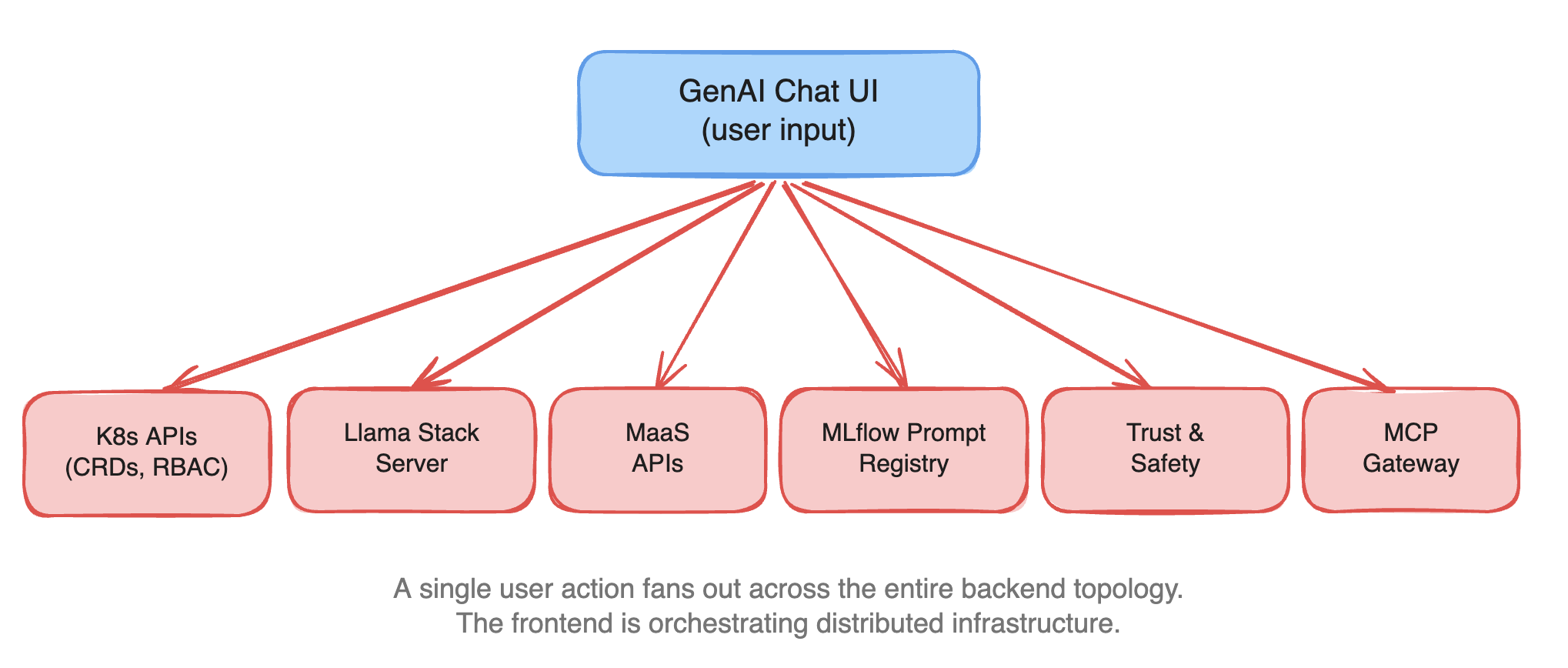
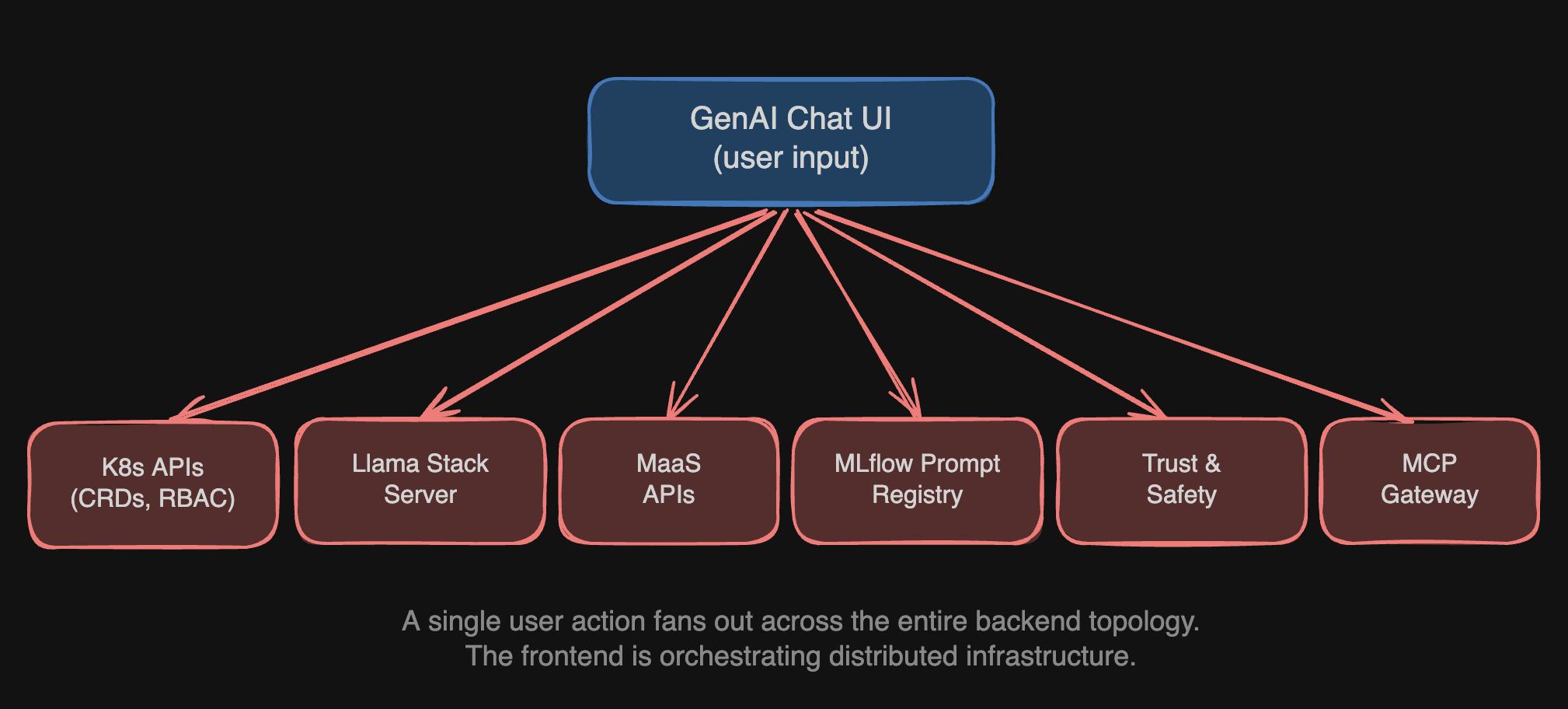
Each of these services has its own authentication model, its own API contract, its own failure modes. The frontend developer is no longer building UI. They are writing a distributed service orchestrator in TypeScript.
2. Team Scaling
A monolithic dashboard creates a single organizational bottleneck. As the platform grows (notebooks, model serving, model registry, pipelines, GenAI features), more teams ship through the same codebase. Ten or more feature teams sharing one monolithic repository means:
- Merge conflicts on shared components and utilities
- Shared test infrastructure where one team's failure blocks all deployments
- Coordinated release cycles that reduce each team's ability to ship independently
- Implicit coupling through shared state, routing, and API clients
- Review bottlenecks as Staff Engineers must assess the blast radius of every change across the entire codebase
The pace of AI innovation compounds this further. New capabilities (GenAI chat, agentic workflows, model catalogs) emerge faster than backend services can stabilize. The UI often needs to start development before the backend APIs are finalized. In a monolith with no abstraction layer, that means the UI team is blocked until the backend is ready, or builds against unstable APIs that change underneath them.
Conway's Law makes this inevitable. A monolithic codebase produces monolithic team dynamics. Adding developers does not add velocity; it adds coordination overhead.
3. Upstream-First Open Source Model
Red Hat's upstream-first model means that features should originate in open-source communities and flow downstream into enterprise products. This principle is well-established for backend services and operators, but it must apply equally to the UI layer. Enterprise AI platforms do not sit on a single upstream project. They integrate across multiple communities: Kubeflow for model registry, model catalog, and notebooks, MLflow for experiment tracking, and others, each with its own governance, release cadence, and contribution model.
For Red Hat AI specifically, code must flow across at least three layers:
- Features ideally start upstream in the relevant community (Kubeflow Model Registry/Hub, Kubeflow Notebooks, and others)
- Get configured and integrated in Open Data Hub
- Get extended with enterprise capabilities in Red Hat AI
A monolithic dashboard cannot cleanly separate what belongs upstream from what is enterprise-specific. You cannot donate part of a monolith to one community while keeping another part proprietary for a different one. The result is one of two failure modes: either the enterprise product forks and diverges from upstream (creating a maintenance burden that grows with every release and every community), or upstream contributions stall because extracting community-appropriate code from an enterprise monolith requires surgical effort on every contribution.
In isolation, each pressure has a textbook solution. But these three do not exist in isolation. They compound. Split the codebase for team velocity, and you still have Kubernetes API calls scattered across every micro-frontend. Add a backend abstraction layer, and you still cannot separate upstream code from enterprise code. Clean up module boundaries for upstream contribution, and you still have eight teams bottlenecked on shared infrastructure. Fix one, and the other two remain. Fix two, and the third undermines them. The architecture must address all three at once.
Why the Naive Approach Fails
The natural first response to these pressures: split the frontend into micro-frontends. Give each team their own independently deployable UI module. Problem solved?
Not quite. Micro-frontends address team velocity: independent development, independent deployment, independent release cycles. But they leave the other two pressures untouched.
Kubernetes and AI Services Coupling Remains
Splitting the monolith into micro-frontends does not change what each frontend calls. The notebook micro-frontend still orchestrates four or more Kubernetes API calls. The GenAI micro-frontend still reaches across Llama Stack, MaaS endpoints, MLflow, and Kubernetes APIs directly. Every frontend developer in every team still needs to understand both Kubernetes resource lifecycle and the API contracts of multiple AI services.
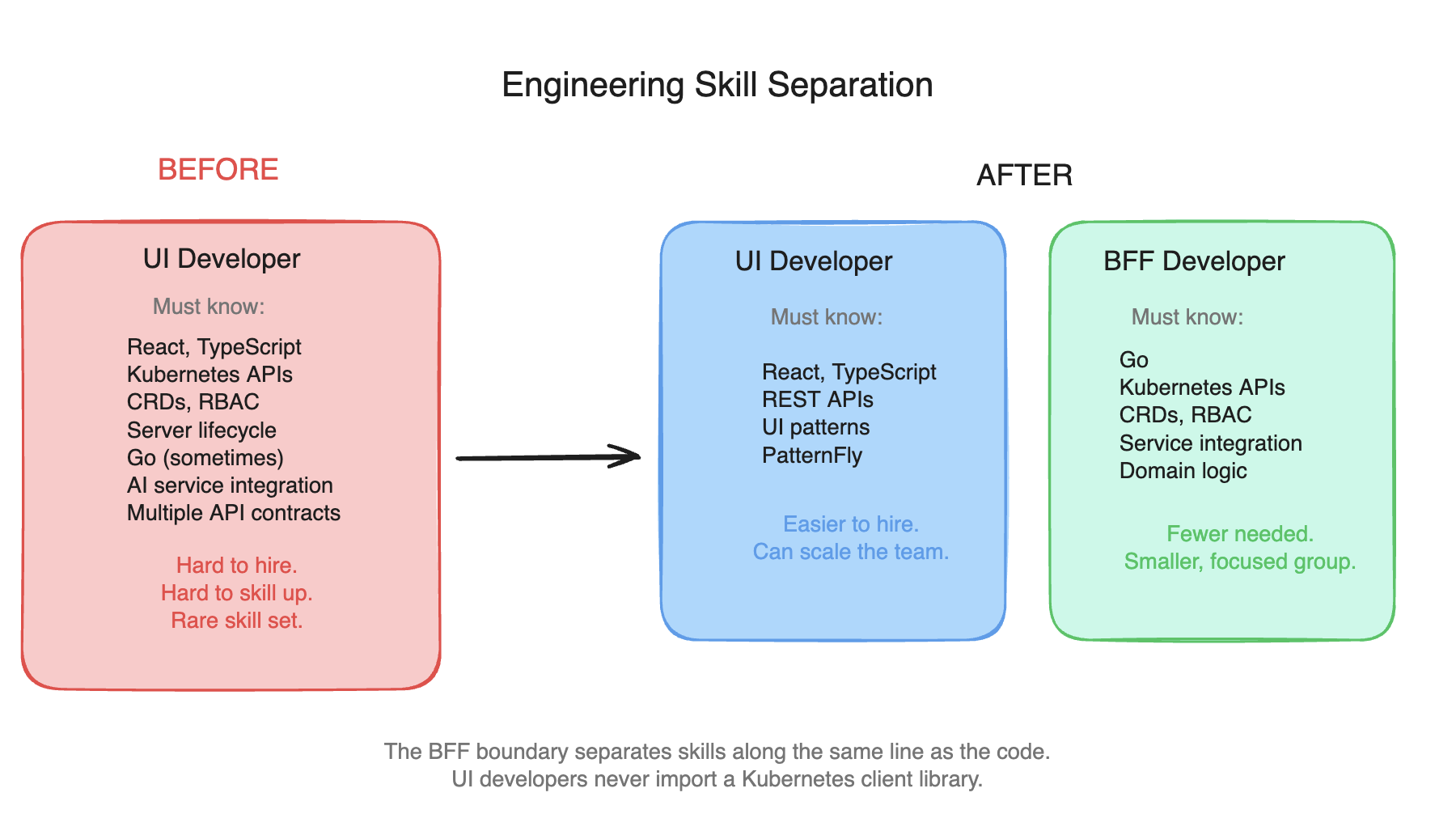
The rare skill set problem (engineers who understand modern frontend development, Kubernetes resource lifecycle, and AI service integration) is now distributed across more teams. Instead of one team struggling to hire, ten teams struggle to hire. The supply of engineers who can write React components, debug Kubernetes RBAC policies, and integrate with Llama Stack or MLflow has not increased. It is simply competed for across more positions.
Upstream Boundaries Remain Broken
Micro-frontends split code by feature domain, but they do not create upstream-downstream boundaries. Enterprise-specific orchestration logic (RBAC checks, multi-tenancy, custom resource extensions) still lives alongside community code within each micro-frontend. The extraction problem persists at a smaller scale within each module.
Without a mechanism to separate what belongs upstream from what belongs downstream, micro-frontends create more boundaries to manage but do not solve the contribution challenge.
What Is Actually Missing
The micro-frontend decomposition addresses the wrong boundary. Team velocity is a symptom. The structural problems are:
- Frontend code owns infrastructure concerns. UI components are responsible for Kubernetes resource orchestration, a responsibility that belongs behind an API boundary.
- No upstream-downstream separation mechanism. Code that should exist in Kubeflow and code that should only exist in Red Hat AI live in the same modules with no architectural seam between them.
- The hiring constraint is architectural, not organizational. Requiring every frontend developer to understand Kubernetes is not a staffing problem. It is a missing abstraction.
Micro-frontends solve the team scaling pressure. But without addressing Kubernetes API coupling and upstream-first contribution, they create smaller monoliths with the same structural problems.
The architecture needs three simultaneous decompositions, not just one.
The Boundary That Actually Matters
The solution is not one decomposition but three, applied simultaneously. Each addresses a different pressure, and each requires the others to work.
| Pressure | Decomposition | Boundary |
|---|---|---|
| Team scaling | Organizational design | Enabling team + stream-aligned teams (Team Topologies) |
| K8s and AI services API coupling | Backend for Frontend | Thin Golang translation layer per module |
| Upstream-first contribution | Module Federation + Extensions | Runtime composition with upstream/downstream extension points |
These are not independent choices. The organizational design determines team ownership. Module Federation determines deployment boundaries. The BFF determines the API boundary. Remove any one and the remaining two cannot hold.
Organizational Design: The Reverse Conway Maneuver
Before touching code, the team structure must change. Skelton and Pais describe this as the Reverse Conway Maneuver: instead of letting the architecture emerge from existing team structure, you design the team structure you want and then shape the architecture to match.
Two team types matter here:
Enabling team. Owns the modular architecture platform itself: the shared libraries, the extension mechanism, the developer experience tooling, the golden paths for onboarding. This team does not build features. It builds the conditions under which feature teams can ship independently. The goal is explicit: enable domain teams to self-serve, then step back. If the enabling team becomes a bottleneck, it has failed.
Stream-aligned teams. Own individual feature domains: Model Registry, GenAI Studio, Model Serving, Notebooks, Pipelines. Each team has full ownership of their module: frontend code, BFF code, API contracts, tests, deployment. They develop and iterate independently, merging, testing, and validating on their own cadence, even though the product ships as a coordinated release.
This is not a reorg for the sake of restructuring. It is an architectural precondition. Without this split, any technical decomposition will be fought by the organizational forces that Conway's Law describes. The monolithic team will produce monolithic software regardless of how many package.json files you create.
Frontend Boundary: Module Federation
Webpack Module Federation provides the runtime composition mechanism. Each feature module is loaded independently at runtime via a remote entry point. The host application discovers and loads modules without compile-time coupling.
Core libraries (React, react-router, PatternFly) are declared as shared singletons so that all modules use a single instance. Each module declares its federation metadata in its own package.json, and the build system auto-discovers modules by scanning the monorepo for packages that export an ./extensions entry point. No manual registration, no routing configuration file that every team must edit. A module exists when its package exports extensions.
But Module Federation alone only solves the deployment boundary. What makes this work for a platform, rather than just a collection of independently loaded SPAs, is the extension mechanism. That gets its own section below.
Backend Boundary: Backend for Frontend
Many micro-frontend architectures already include a BFF layer. What makes this case distinct is why the BFF is necessary: not just for API aggregation, but as the boundary that absorbs Kubernetes and AI services complexity away from frontend engineers. The BFF pattern places a thin, domain-specific translation layer between the frontend and the backend services. Each module owns its own BFF. A module is not just a React application. It is a React frontend paired with a Golang BFF, connected by an OpenAPI contract.
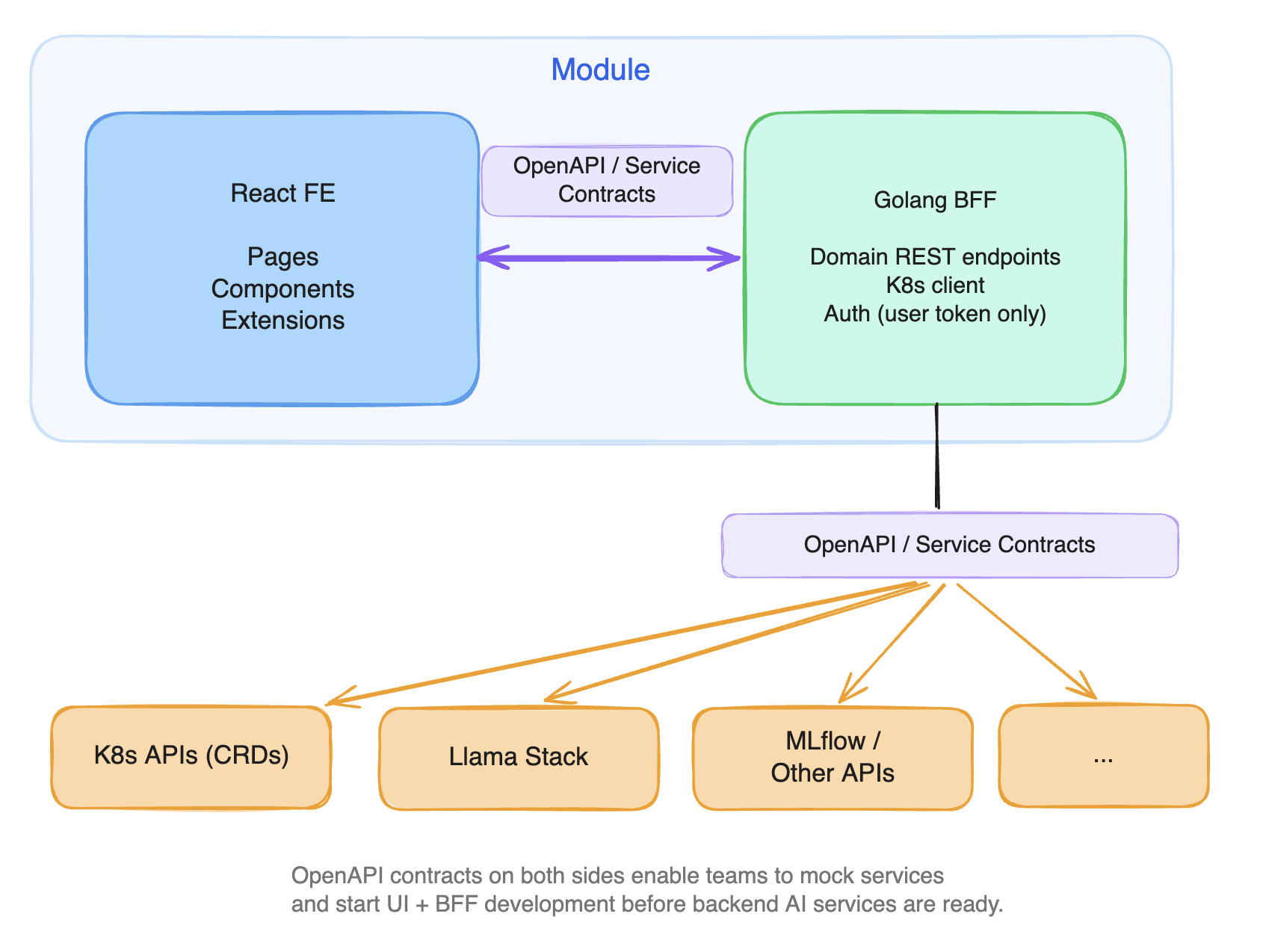
The OpenAPI contracts on both sides of the BFF (between frontend and BFF, and between BFF and backend services) are what enable teams to start building before the AI services are ready. With the contract defined, the BFF can mock backend responses at the repository layer while the service teams build the real implementation. Frontend and BFF development proceed in parallel from day one, even when the underlying AI service does not yet exist.
The choice of Go for the BFF is not incidental. The platform's backend services are Kubernetes-native: operators, controllers, and CRD-based APIs built on client-go and controller-runtime. Writing the BFF in Go means sharing types, client libraries, and testing infrastructure with those services directly. The BFF reuses the same Kubernetes client bindings, the same typed resource definitions, and can run integration tests against envtest (an in-memory Kubernetes API server) without standing up a cluster. A Node.js BFF would require maintaining a parallel set of Kubernetes client bindings, re-implementing types that already exist in Go, and losing access to the testing tools the rest of the platform uses. Go also fits the BFF's role as a thin translation layer: compiled, low memory footprint, and native concurrency for watching multiple Kubernetes resources simultaneously.
The BFF absorbs three categories of complexity that do not belong in the browser:
Kubernetes orchestration. The notebook creation flow (PVC, ConfigMaps, Secrets, Notebook CR) becomes a single REST call from the frontend. The BFF handles resource creation order, owner references, status watching, and error aggregation. Frontend developers call POST /api/notebooks and receive a domain-specific response. They never import a Kubernetes client library.
Service topology. The GenAI chat interface calls its BFF. The BFF reaches Llama Stack, MaaS, MLflow, and Kubernetes APIs on behalf of the frontend. The frontend knows one endpoint. The BFF knows the topology.
Authentication boundary. The BFF uses the user's token exclusively: no service accounts, no elevated privileges. It is a pass-through for the user's identity, not an escalation point. This is a deliberate security constraint: the BFF's area of coverage is dashboard-scoped only.
The OpenAPI contract between FE and BFF is the critical boundary artifact. From this contract, TypeScript types are generated for the frontend and Go types for the BFF. The contract is tested: if the BFF response does not match the OpenAPI spec, contract tests fail. This is not documentation. It is an enforceable interface.
// BFF handler pattern — thin translation, not business logic
func (app *App) GetAllRegisteredModelsHandler(w http.ResponseWriter, r *http.Request, ps httprouter.Params) {
client, ok := r.Context().Value(ModelRegistryClientKey).(httpclient.HTTPClientInterface)
if !ok {
app.serverErrorResponse(w, r, errors.New("client not found in context"))
return
}
models, err := app.repositories.ModelRegistry.GetAllRegisteredModels(client, r.URL.Query())
if err != nil {
app.serverErrorResponse(w, r, err)
return
}
app.WriteJSON(w, http.StatusOK, Envelope{Data: models}, nil)
}
A critical architectural distinction: the BFF is not an API gateway. It does not implement rate limiting, circuit breaking, monitoring, or cross-cutting concerns. Those belong on the platform layer (OpenShift, Istio, the service mesh). The BFF's single responsibility is translating between "what the UI needs" and "what the backend services provide." If a BFF starts accumulating middleware, it has crossed its boundary.
The BFF decomposition transforms the hiring problem. Before: every frontend developer must understand Kubernetes APIs, RBAC, CRDs, and server-side resource lifecycle, a rare and expensive skill set. After: UI developers work with REST APIs, component libraries, and familiar frontend patterns. BFF developers, a smaller specialized group, own the Kubernetes and service integration layer in Go. The skills are separated along the same boundary as the code.
Module and Open Source Extension Mechanism
Most micro-frontend articles stop at runtime composition: load modules independently, share a few libraries, done. That misses the hardest problem for platforms built on open-source foundations: how do you maintain a single codebase that serves both upstream and downstream without forking?
Without a solution, teams face two failure modes:
- Fork and diverge. Copy the upstream module, modify it for enterprise needs, and maintain two codebases that drift apart with every upstream release.
- Patch and drift. Maintain the upstream module as-is and layer enterprise features through brittle patches that break on every rebase.
Both paths create maintenance burdens that grow linearly with the number of modules and the pace of upstream development. Neither scales.
Extension Points as Architecture
The solution is an extension point system that mirrors the same pattern on both the frontend and the BFF. Upstream modules define extension points: typed contracts that describe what can be extended. Downstream modules provide extension implementations: concrete code that fulfills those contracts. The module itself does not know whether it runs in Kubeflow, Open Data Hub, or Red Hat AI. It only knows that certain extension points may or may not have implementations available.
An extension point is a typed declaration with a namespace convention:
// Extension point: a typed contract for what can be plugged in
// Namespace convention: domain.section[/sub-section]
type RouteExtension = Extension<'app.route', {
component: ComponentCodeRef;
path: string;
}>;
type NavItemExtension = Extension<'app.navigation/href', {
id: string;
title: string;
href: string;
section?: string;
}>;
Domain-specific modules define richer extension points. Model Serving, for example, declares extension points for platform registration, deployment wizards, status fetching, and delete flows, each one a typed contract that other modules can implement:
// Model Serving extension points — each platform (KServe, ModelMesh, NIM)
// provides implementations for these contracts
type ServingPlatformExtension = Extension<'model-serving.platform', {
id: string;
name: string;
manage: ComponentCodeRef;
}>;
type DeploymentWizardField = Extension<'model-serving.deployment/wizard-field', {
id: string;
component: ComponentCodeRef;
platforms: string[];
}>;
type DeleteDeployment = Extension<'model-serving.platform/delete-deployment', {
platformId: string;
component: ComponentCodeRef;
}>;
A module provides extensions by exporting them from its package:
// Model Registry extensions — provides routes, nav items,
// and cross-module integration points
const extensions: Extension[] = [
{
type: 'app.route',
properties: {
path: '/modelRegistry',
component: () => import('./src/ModelRegistryRoutes'),
},
},
{
type: 'app.navigation/href',
properties: {
id: 'model-registry',
title: 'Model Registry',
href: '/modelRegistry',
section: 'model-registry',
},
},
{
type: 'model-catalog.page/banner',
properties: {
id: 'validated-models-banner',
component: () => import('./src/modelCatalog/ValidatedModelsBanner'),
},
},
];
export default extensions;
Extensions are lazily loaded: the component code is not fetched until the extension point is rendered. And they are filtered at runtime through feature flags, so the same codebase can enable or disable extensions based on deployment context:
// Extension filtering — same codebase, different capabilities per deployment
class PluginStore {
private isExtensionInUse(extension: LoadedExtension): boolean {
return (
(extension.flags?.required?.every((f) => this.featureFlags[f] === true) ?? true) &&
(extension.flags?.disallowed?.every((f) => this.featureFlags[f] === false) ?? true)
);
}
}
Cross-Module Extensions in Practice
The real power of extension points is not within a single module. It is across modules that have no direct dependency on each other.
Consider the "Deploy" button on a Model Registry version page. Model Registry is an upstream Kubeflow module. Model Serving is a separate module with its own BFF. The user expects a single "Deploy" button that takes a registered model and deploys it as an inference endpoint. But Model Registry should not import Model Serving code. They are independent modules with independent lifecycles.
Model Registry defines the extension point contract, a typed declaration of what it needs:
// model-registry extension point: "I can host a deploy modal if someone provides one"
type ModelRegistryDeployModalExtension = Extension<
'model-registry.model-version/deploy-modal',
{
useAvailablePlatformIds: CodeRef<() => string[]>;
modalComponent: CodeRef<
React.ComponentType<{
modelDeployPrefill: {
data: ModelDeployPrefillInfo;
loaded: boolean;
error: Error | undefined;
};
onClose: () => void;
}>
>;
}
>;
Model Serving provides the implementation, lazily loaded and gated behind a feature flag:
// model-serving extension: "I provide the deploy modal for model-registry"
{
type: 'model-registry.model-version/deploy-modal',
properties: {
useAvailablePlatformIds: () =>
import('../modelRegistry/useAvailablePlatformIds').then((m) => m.default),
modalComponent: () =>
import('../modelRegistry/PreWizardDeployModal').then((m) => m.PreWizardDeployModal),
},
flags: {
required: [SupportedArea.MODEL_SERVING],
},
},
Model Registry discovers this at runtime through the plugin SDK, no import, no compile-time coupling:
// model-registry resolves the extension at runtime
const DeployModalExtension: React.FC<Props> = ({ mv, render }) => {
const [extensions, extensionsLoaded] = useResolvedExtensions(
isModelRegistryDeployModalExtension
);
const isModalAvailable = extensionsLoaded && extensions.length > 0;
// If no extension is found (model-serving not installed): button does not render
// If platforms are unavailable: button renders disabled with admin tooltip
// If platforms are available: button renders enabled, opens model-serving's modal on click
return render(buttonState, onOpenModal, isModalAvailable);
};
The consequence: if Model Serving is not installed in the cluster, the Deploy button does not exist. It does not render disabled. It does not render with an error. It is absent. The Model Registry page is complete without it. If Model Serving is installed but no serving platforms are configured, the button renders disabled with a tooltip telling the administrator what to enable. The UI adapts to the deployment topology at runtime.
This is the pattern that enables upstream-downstream coexistence. Model Registry ships upstream in Kubeflow with its extension point contracts. Model Serving, which may or may not exist in a given deployment, provides implementations downstream. Neither module knows the other exists at build time. The extension type system is the only coupling, and it is a contract, not a dependency.
The Upstream-Downstream Flow
This mechanism enables a single codebase to serve multiple deployment targets. Features flow through layers without forking:
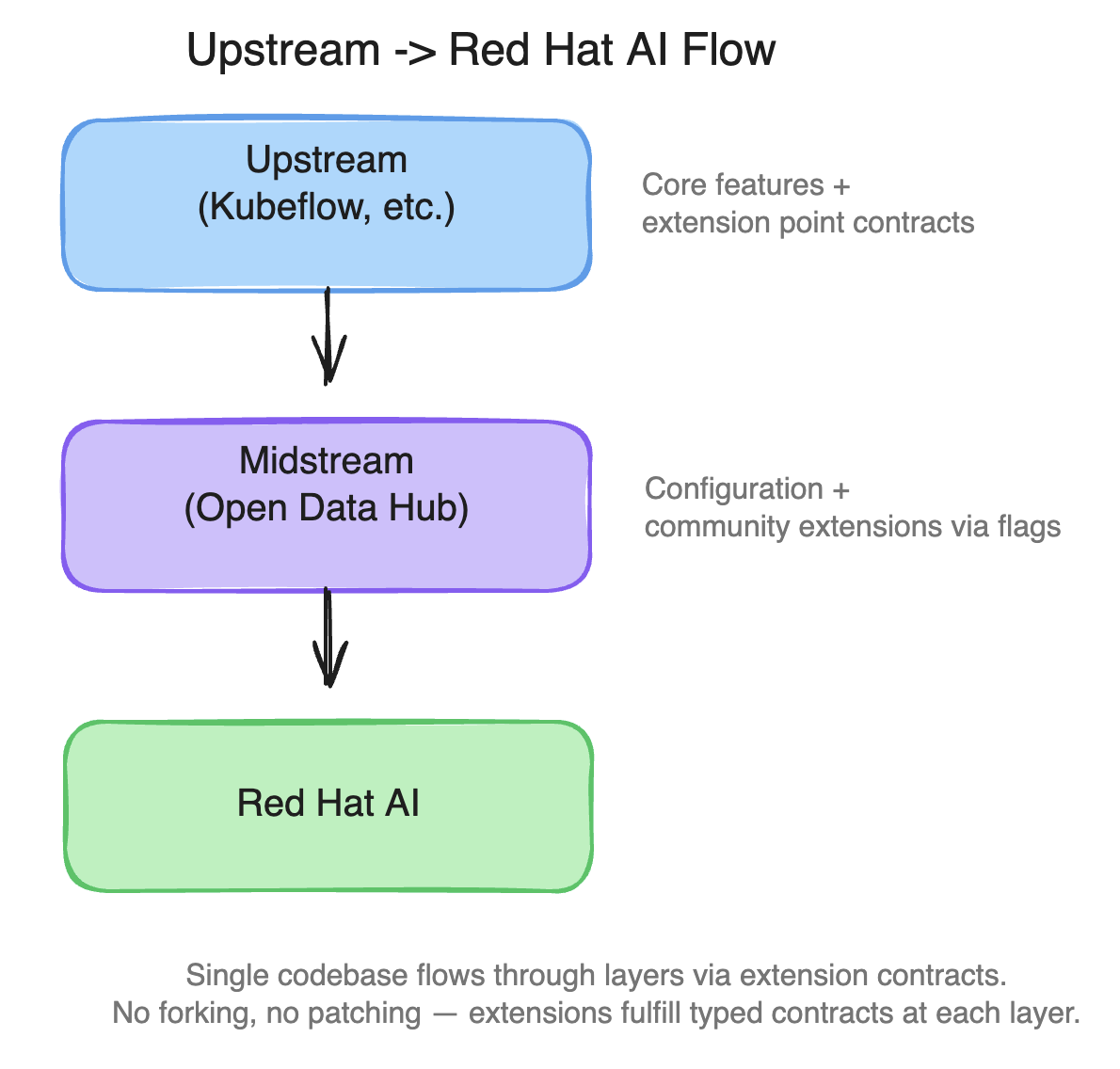
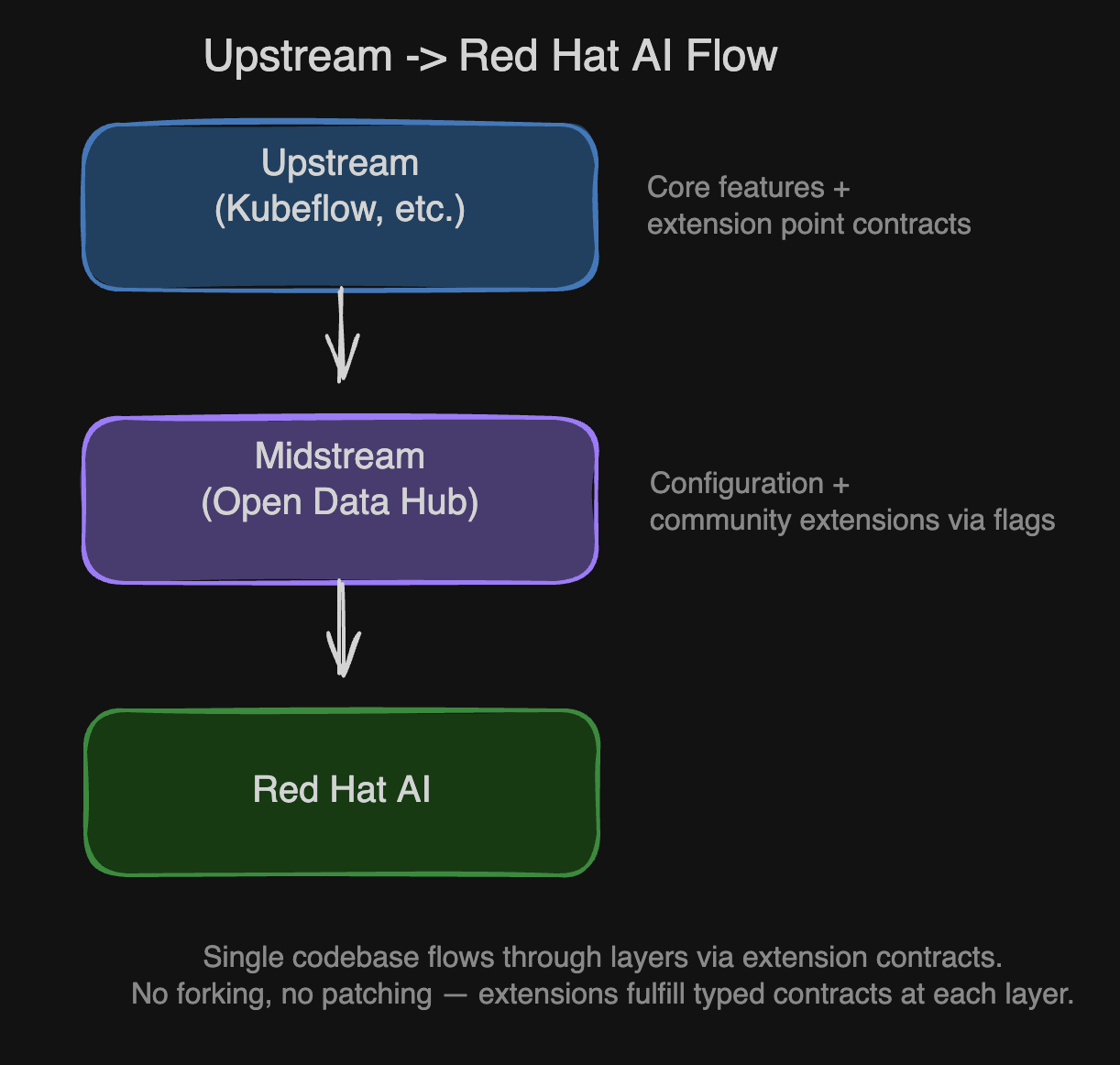
The upstream module is consumed via git subtree: the actual upstream code lives in each module's package directory. Downstream extensions are provided alongside it, not patched into it. When upstream releases, the subtree is updated and the downstream extensions continue to work because they depend on typed contracts, not on internal implementation details.
The same extension pattern applies to the BFF layer, though as an exception rather than the rule. Most BFF code is upstream-clean. But some capabilities (OpenShift-specific integrations, for instance) do not belong in upstream Kubeflow. In these cases, the BFF defines extension points that downstream code can implement, mirroring the frontend pattern. These are the minority of cases; the BFF deep dive is a topic for a dedicated follow-up post.
This is the architectural seam that micro-frontends alone cannot provide. The extension point is not just a plugin API. It is the upstream-downstream boundary encoded in the type system.
Operational Consequences
Architecture is validated by its operational outcomes. The decomposition described above (org design, Module Federation, BFF, extension mechanism) produces measurable changes in how teams develop, hire, and contribute upstream.
Clusterless Development
The BFF boundary enables a development workflow that would be impossible in the monolith: frontend development without a Kubernetes cluster.
In the monolithic architecture, every UI change required a running cluster. Fixing a button label meant standing up notebooks, model serving, and the full Kubernetes control plane, or waiting for a shared development environment that was frequently disrupted by concurrent development.
With the BFF in place, each module's BFF supports a mock mode. The mock operates at the repository layer, not the API layer: the BFF's internal data access is replaced with in-memory test data, while the REST endpoints, request validation, and response shaping remain real. Frontend developers start immediately with mocked BFF endpoints and build against the actual API contract.
A module that cannot be mocked at the BFF layer is not truly decoupled. If the frontend requires a live cluster to render, the BFF has leaked infrastructure concerns upward. Mock-ability is a litmus test for boundary correctness.
This changes the development flow fundamentally:
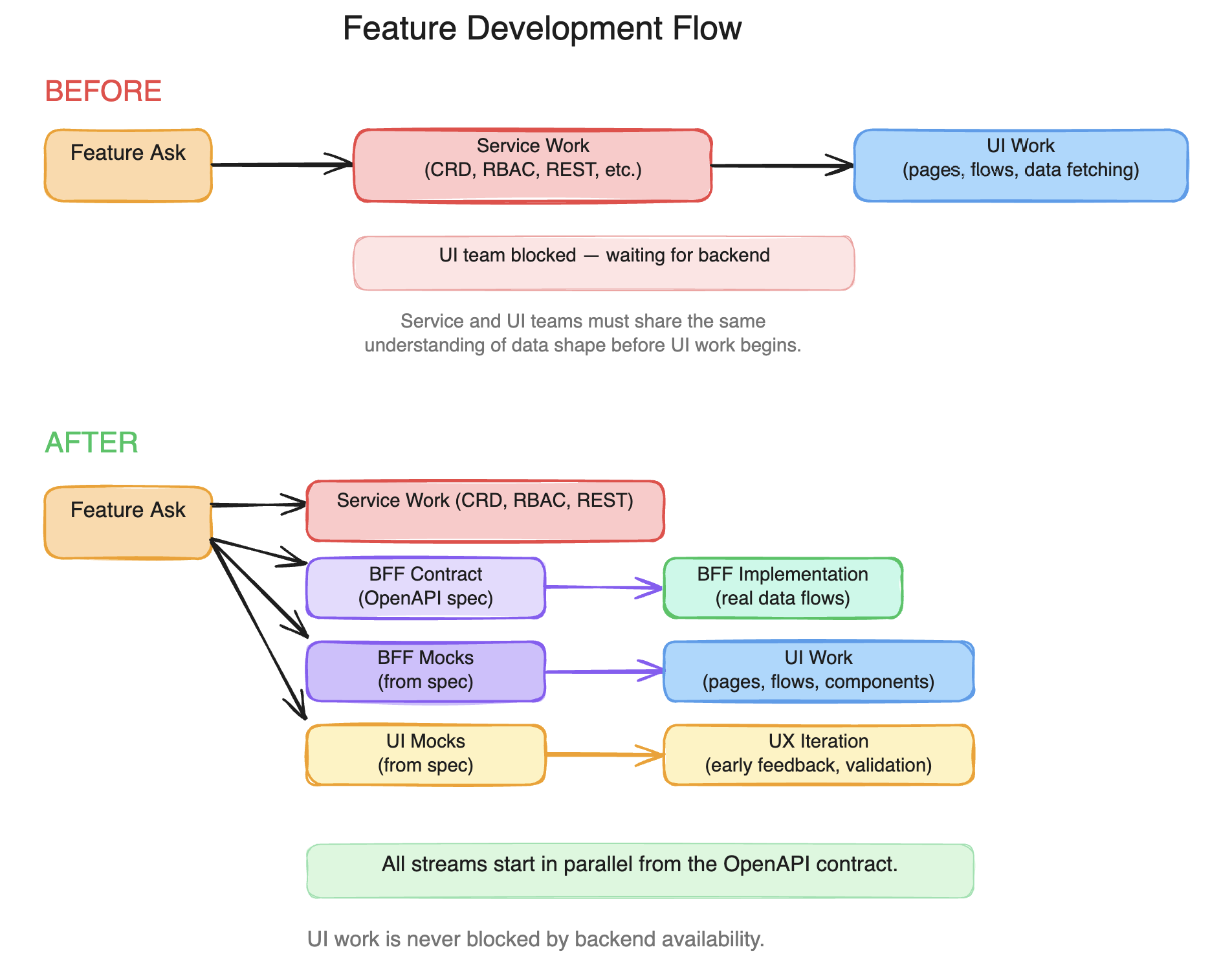
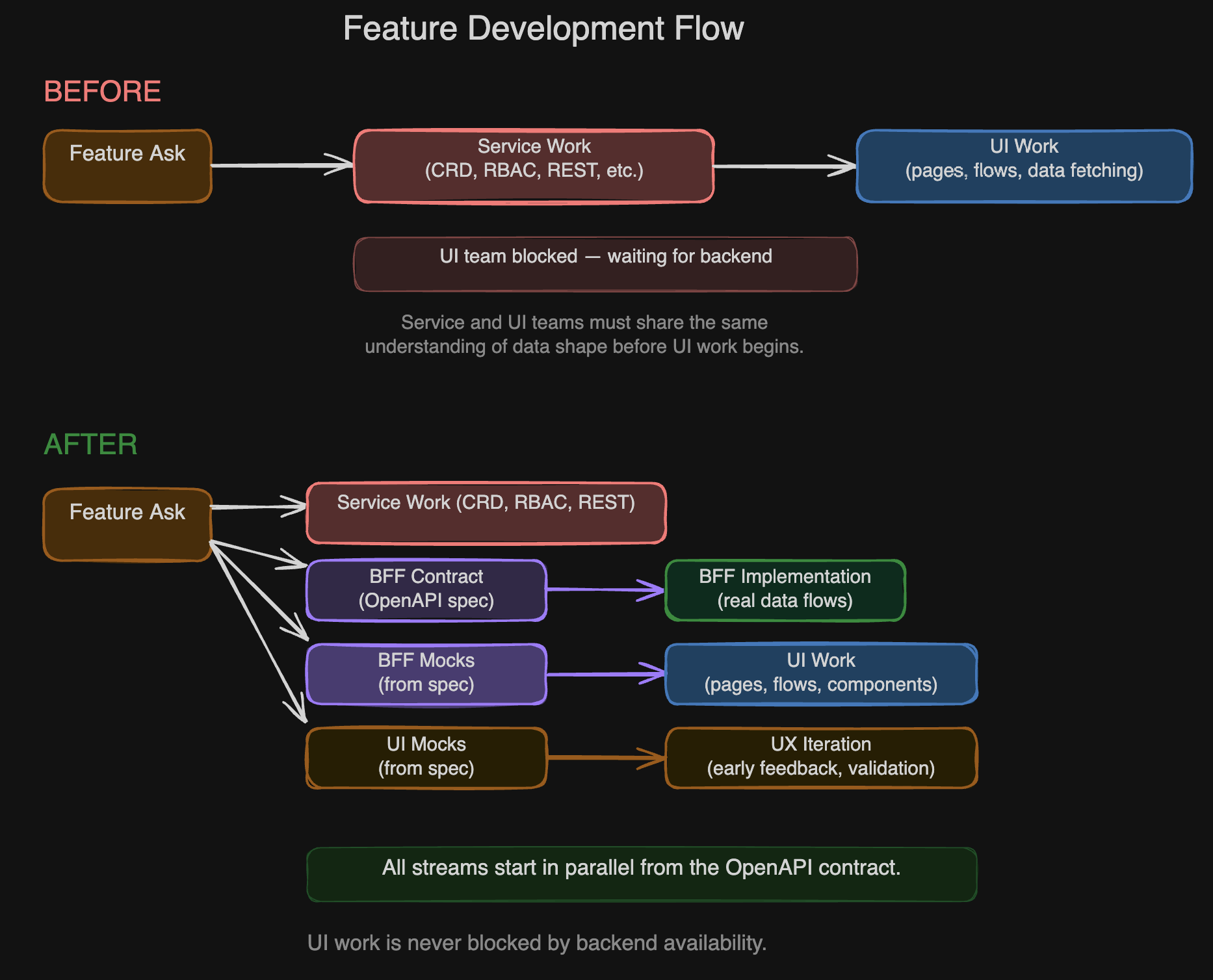
The shift is structural, not incremental. In the old flow, the UI team would often wait for the CRD, the REST API, and the service team's understanding of the data shape before meaningful frontend work could begin. Early UI work was limited to layouts that did not touch real data. Useful, but not the bottleneck.
With early mocks and parallel streams, iterating on what it means to have a good user experience becomes possible before any backend service is deployed. Teams discover UX problems ("we have an RBAC gap here" or "this flow needs a preview endpoint") weeks earlier, when the cost of changing the API contract is low.
Team Velocity
The organizational and technical decomposition together produce compounding velocity gains:
- 4 federated modules in production (Model Registry, Model Catalog, GenAI Studio, Model Serving) and 6+ in progress (Notebooks, Pipelines, EvalHub, AutoRAG, and others), each owned by a stream-aligned team
- 8+ teams shipping independently, developing and validating on their own cadence within a coordinated release
- Self-onboarding golden path: documentation, templates, and a module installer that lets teams scaffold a complete module (React FE + Golang BFF + OpenAPI contract + CI pipeline) without bottlenecking the enabling team
- External team onboarding. Teams outside the original organization have onboarded through workshops, validating that the architecture supports teams who did not build it
The enabling team's success metric is absence: when stream-aligned teams stop needing help, the platform is working. The golden path (documentation, templates, example modules) is designed to make the enabling team unnecessary for routine module development.
Upstream Impact
The modular architecture directly enabled Red Hat's upstream contribution strategy:
- Red Hat is the #1 contributor to Kubeflow over the past year. A significant part of that position comes from UI engineers now contributing upstream alongside backend teams, something that would be impossible if every contribution required extracting code from a monolith
- Model Registry was the first Red Hat UI module integrated into upstream Kubeflow (Kubeflow 1.10), delivered as a self-contained module with its own BFF, not as a patch to the Kubeflow dashboard
- PatternFly themed as MUI was accepted as a valid Kubeflow upstream component library, enabling Red Hat's design system to participate in Kubeflow's MUI-based ecosystem without requiring upstream to adopt PatternFly
- Single codebase serves both Kubeflow and Red Hat AI. The extension mechanism eliminates the fork-or-patch dilemma for every module
Each of these outcomes is a direct consequence of the architectural boundaries described above. The module boundary enables independent contribution. The extension mechanism enables upstream-downstream coexistence. The BFF enables self-contained modules that can be contributed without dragging Kubernetes orchestration logic into the upstream project.
Context Boundaries and AI Tooling
The same context shrinking that enables human engineers to work independently has a second-order effect: it makes the codebase something AI coding assistants can reason about effectively.
AI coding tools (Claude Code, Copilot, Cursor) reason about code within a context window. The quality of their output degrades as that context grows and as the boundaries between concerns blur. A monolithic codebase where a form component imports Kubernetes client libraries, shares state with RBAC utilities, and calls six backend services directly presents an AI assistant with a context that is both too large and too tangled to reason about effectively.
In the modular architecture, the unit of context is the module: a React frontend, a Golang BFF, and an OpenAPI contract connecting them. An AI assistant working on a notebook form bug needs the module's frontend code and its OpenAPI contract. It does not need to understand Kubernetes CRDs, RBAC policies, or the service topology behind the BFF. The BFF boundary that separates infrastructure concerns from UI concerns for human engineers serves the same function for AI tools.
The OpenAPI contracts serve double duty. They are the enforceable interface between frontend and BFF, and they are machine-readable documentation that AI tools consume directly. The typed extension points provide explicit integration boundaries: an AI assistant can see exactly where modules connect and what contracts govern those connections, without reverse-engineering implicit coupling through shared state or import graphs.
A future post will cover how AI-assisted development workflows operate on top of this modular substrate: what changes when AI tools can reason about modules independently, and where the remaining friction lives.
Closing
The Red Hat AI dashboard did not reach its limits because the team lacked frontend skill. It reached them because the UI boundary needed to move.
API coupling, team scaling, and upstream-first contribution are not independent pressures. They reinforce each other. When infrastructure orchestration lives in the browser, when upstream and enterprise code share no architectural seam, and when multiple teams push through a single codebase, the failure mode is predictable: coordination overhead rises, abstraction erodes, and contribution slows.
The response cannot be partial.
Organizational design must separate enabling concerns from stream-aligned feature delivery. The BFF must absorb Kubernetes and service topology complexity so the browser stops acting as a distributed control plane. The extension mechanism must encode the upstream-downstream boundary in typed contracts, so contribution is structural rather than negotiated release by release.
None of these ideas is novel in isolation. Micro-frontends, BFF patterns, and Team Topologies are well documented. What made our case specific was the requirement to apply all three simultaneously, and to treat extension points not as a plugin convenience, but as the seam that prevents fork-or-patch divergence across multiple open-source communities.
This is not about React, or Webpack, or Golang.
It is about placing responsibility in the correct layer.
When that boundary is correct, teams scale. Upstream contribution becomes routine. Frontend engineers build product, not infrastructure orchestrators.
When it is wrong, no amount of modularization will save the system.
The difference is architectural, not procedural.
As AI platforms mature, we expect this separation (interaction layer, orchestration mediation, and extensibility surfaces) to become a common pattern rather than a Red Hat-specific solution.
Follow-up
This post covered the architectural reasoning and its consequences. Several topics deserve dedicated treatment. Each will be a follow-up post:
- BFF architecture deep dive. Internal design of the Golang BFF layer: middleware chains, repository patterns, request validation, and how the translation layer stays thin.
- CSS theming strategy. How PatternFly components render as MUI-compatible in upstream Kubeflow without requiring upstream to adopt a different design system. The theming boundary is its own architectural challenge.
- Independent pod deployments. The path to deploying each module as a separate Kubernetes pod, with independent scaling and lifecycle.
- BFF intercommunication. Cross-module features that require BFF-to-BFF communication and the patterns emerging for them.
- Multi-client support. How the BFF architecture enables multiple frontend clients (dashboard, Jupyter, VS Code extension) consuming the same domain APIs.
- AI-assisted development on a modular codebase. How the modular architecture shapes AI coding tool adoption: context boundaries, contract-driven generation, and what changes when AI assistants can reason about modules independently.